
ComfyUI_AnimeWorlkflow
方便快速的动漫工作流,包含了我进行ai艺术创作的所有流程,看完你也是CUI大神(大嘘
SP:阅读本文的前提是你已经了解了基础的StableDiffusion架构和ComfyUI基础知识,如果你是初学者请先仔细阅读 Tensor Book 潜工具书 ,开源社区的大佬们已经整理好了从入门到入土的全面教程,本文仅展示和介绍我自己常用的工作流,不对细节进行解释说明

A1111
为了方便切换模型和快速调整画风我在各个模块中添加了许多逻辑判断,下面我将逐个讲解
Main
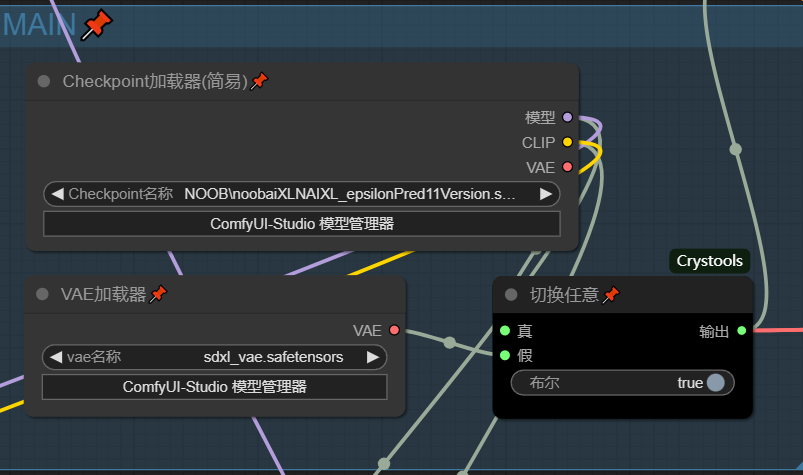
没什么特别的,只是添加了vea选择判断
Laten
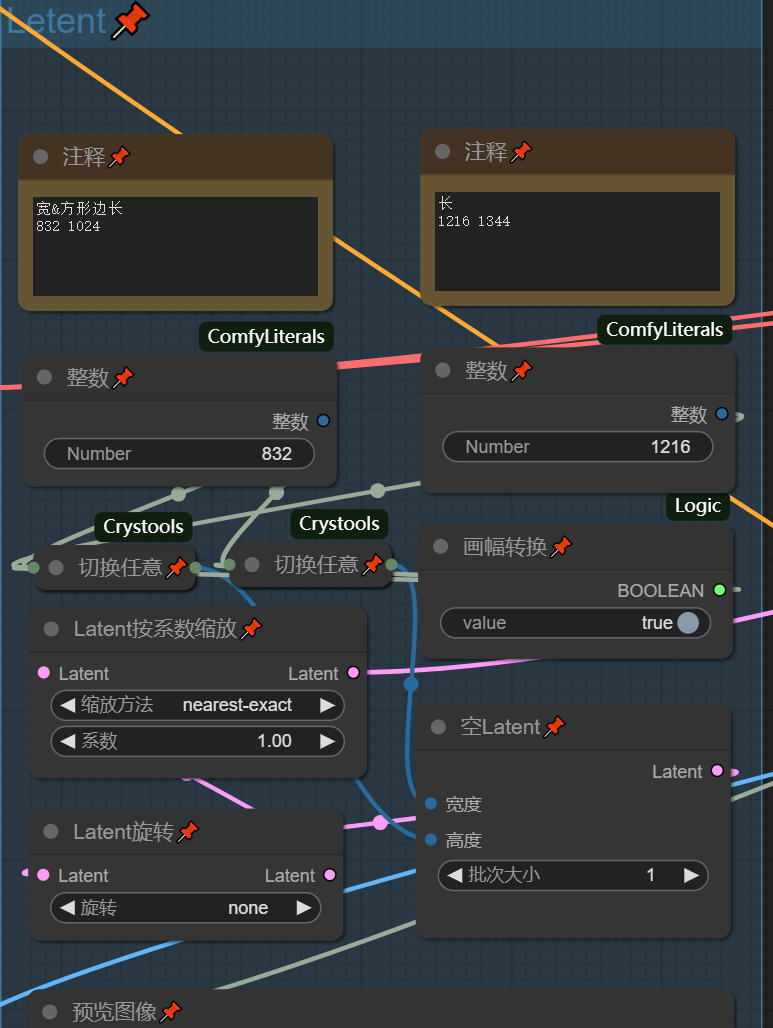
通过画幅转换开关来快速选择矩形或方形画幅
Lora
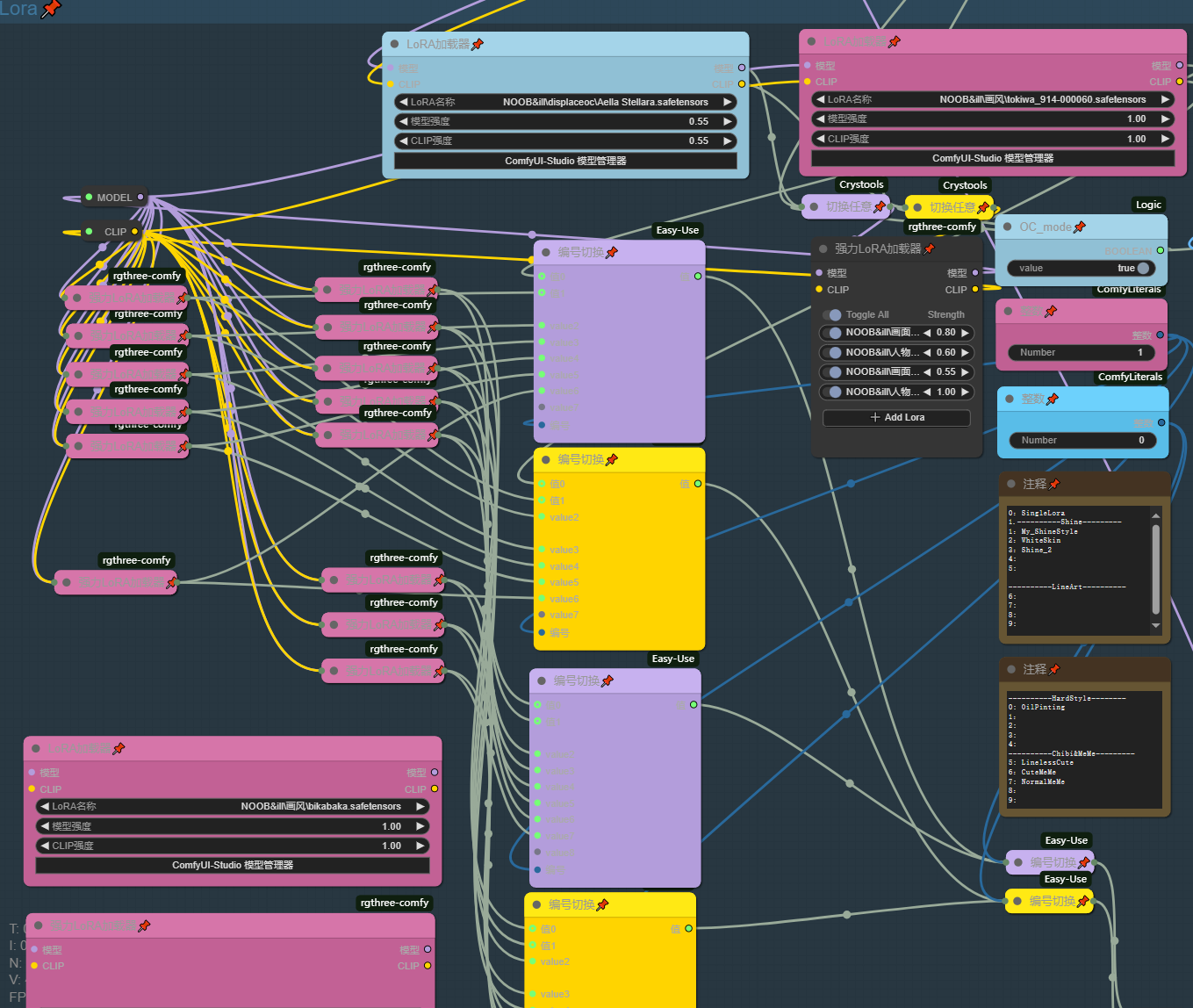
此模块分为角色lora,画面和人物细节lora,画风组合lora,我通过一些简单的逻辑架构实现了对多个lora的快捷控制
角色lora
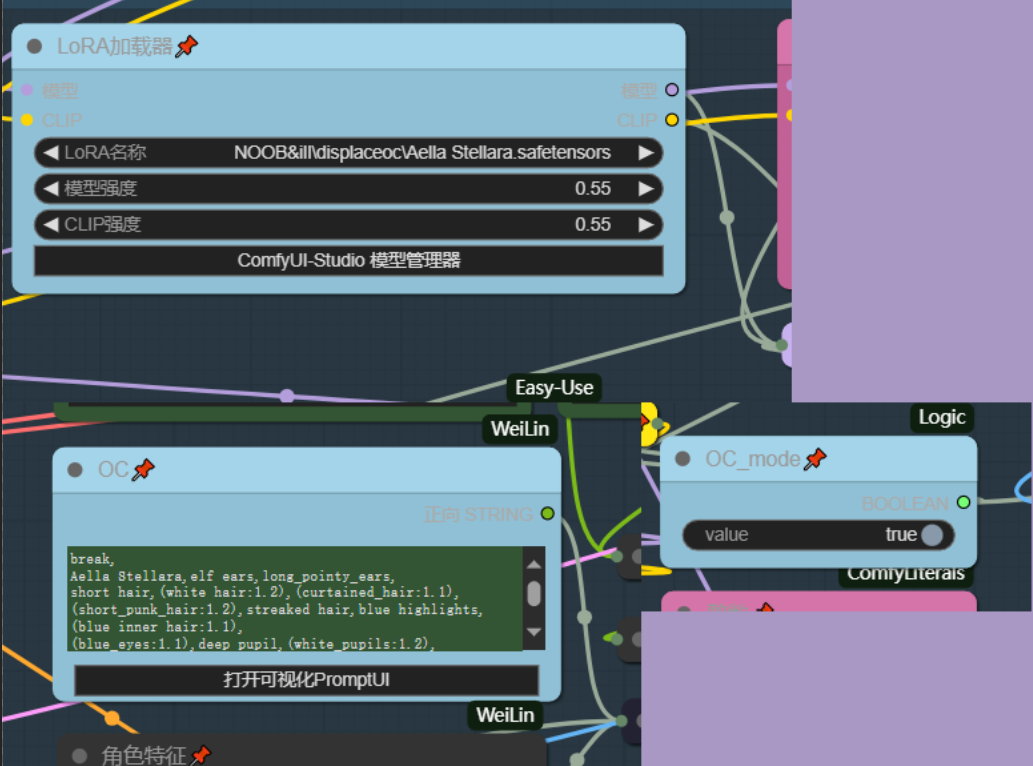
角色lora通过OC_Mode开关判断是否启用,此开关同时也会控制PositivePromote中的OC字符串是否启用
画面和人物细节lora
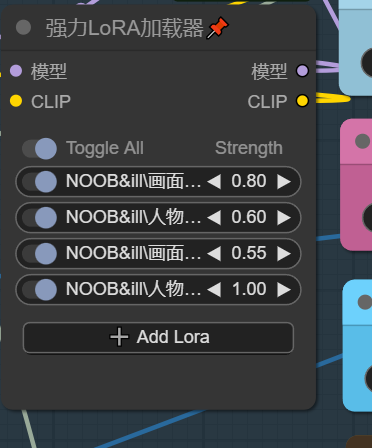
画面和人物细节lora通过一个强力lora加载器来同时加载,在使用某些强烈画风lora时应关闭这些细节lora
画风组合lora
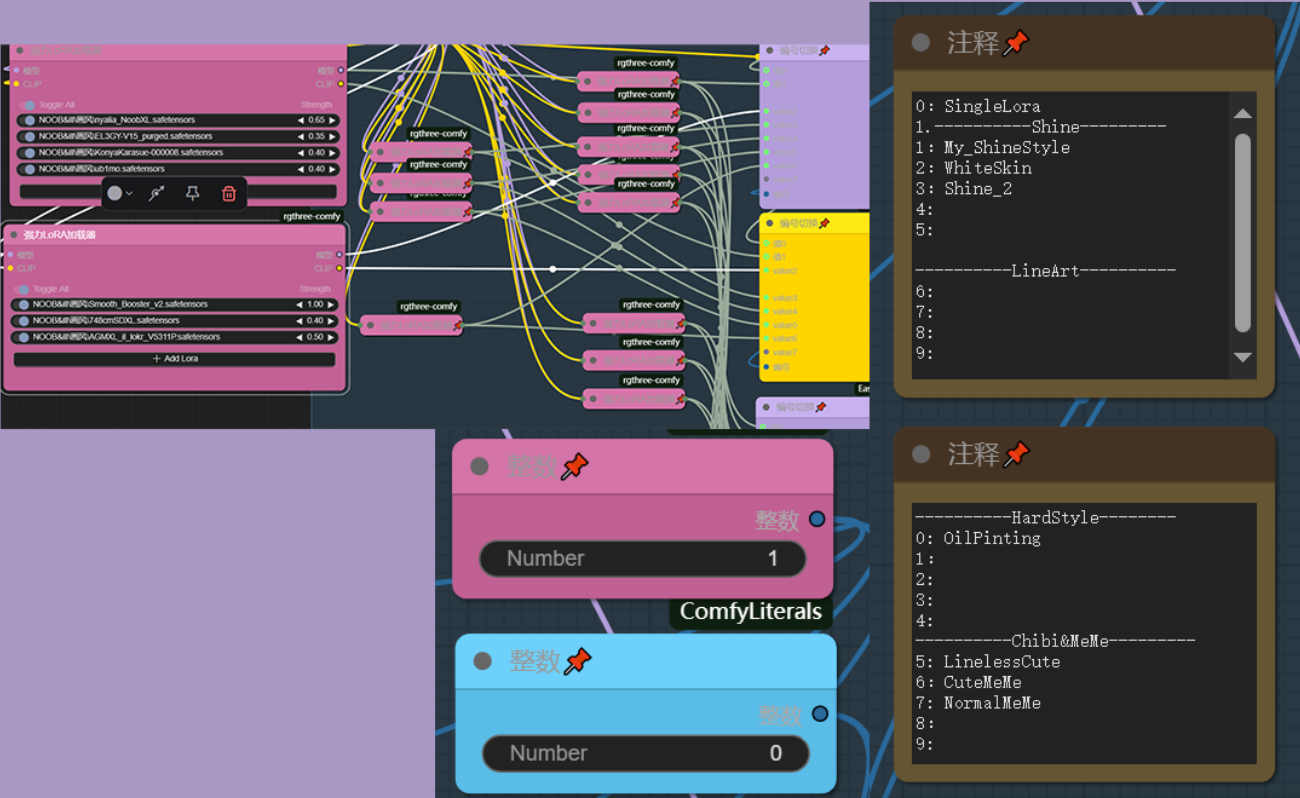
此模块是我设计的简易loramix管理器,有时各种画风lora混合能达到更好的效果,丹这些混合参数却无法被lora管理器记录,因此我使用多个强力lora加载器来记录这些loramix同时用选择索引输出来选择loramix
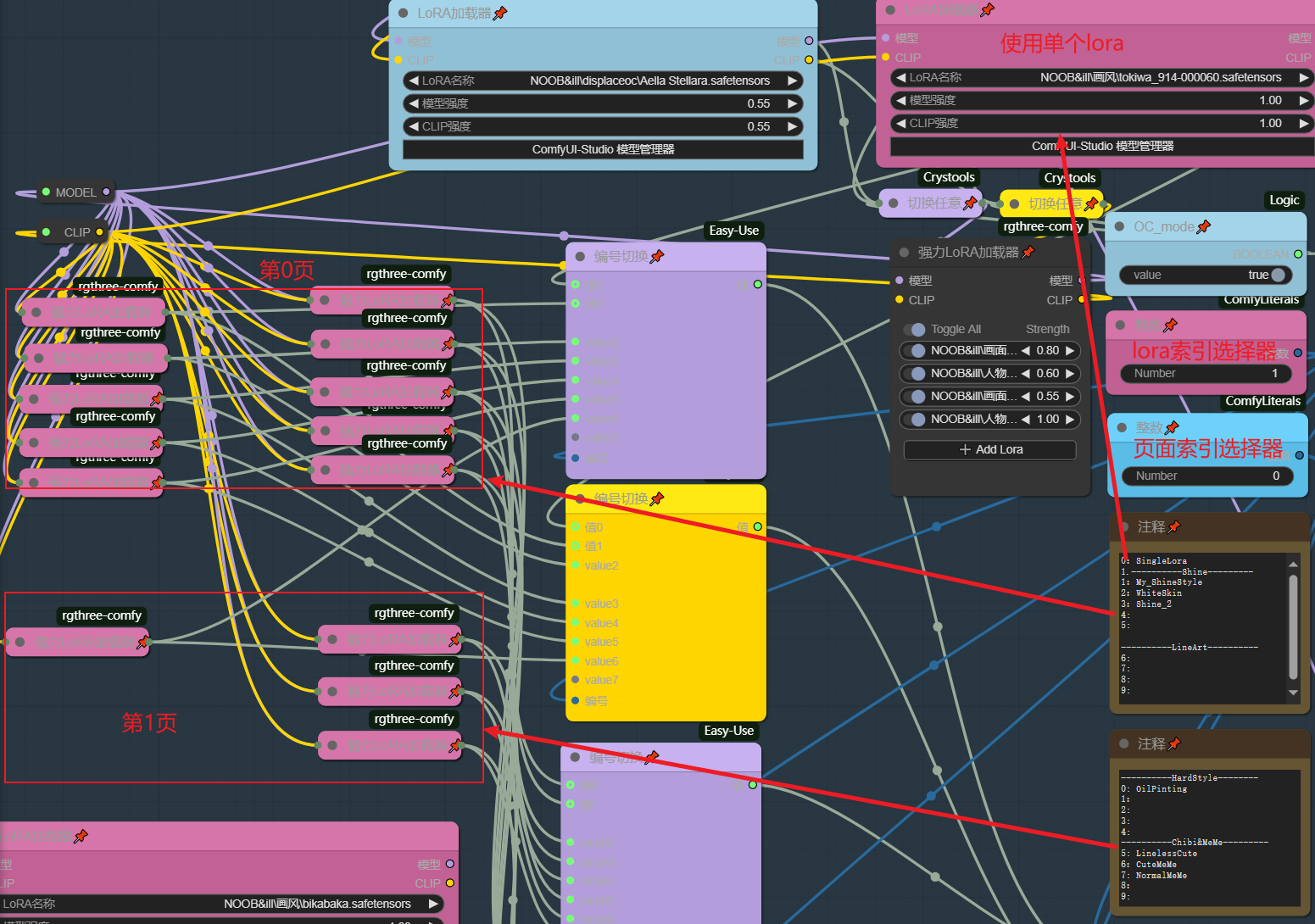
将强力lora加载器展开可添加复数的lora进行混合,这些loramix通过两个索引选择器控制调用,其中粉色的是loramix索引,蓝色的是页索引,当你不想使用画风lora时将粉色的索引选择器按照注释改为空loramix即可
目前我只创建了两页,你可以在空的强力lora加载器中添加自己的loramix并在注释中取名,也参考我的架构去拓展页数
Positive&Nagative Prompt
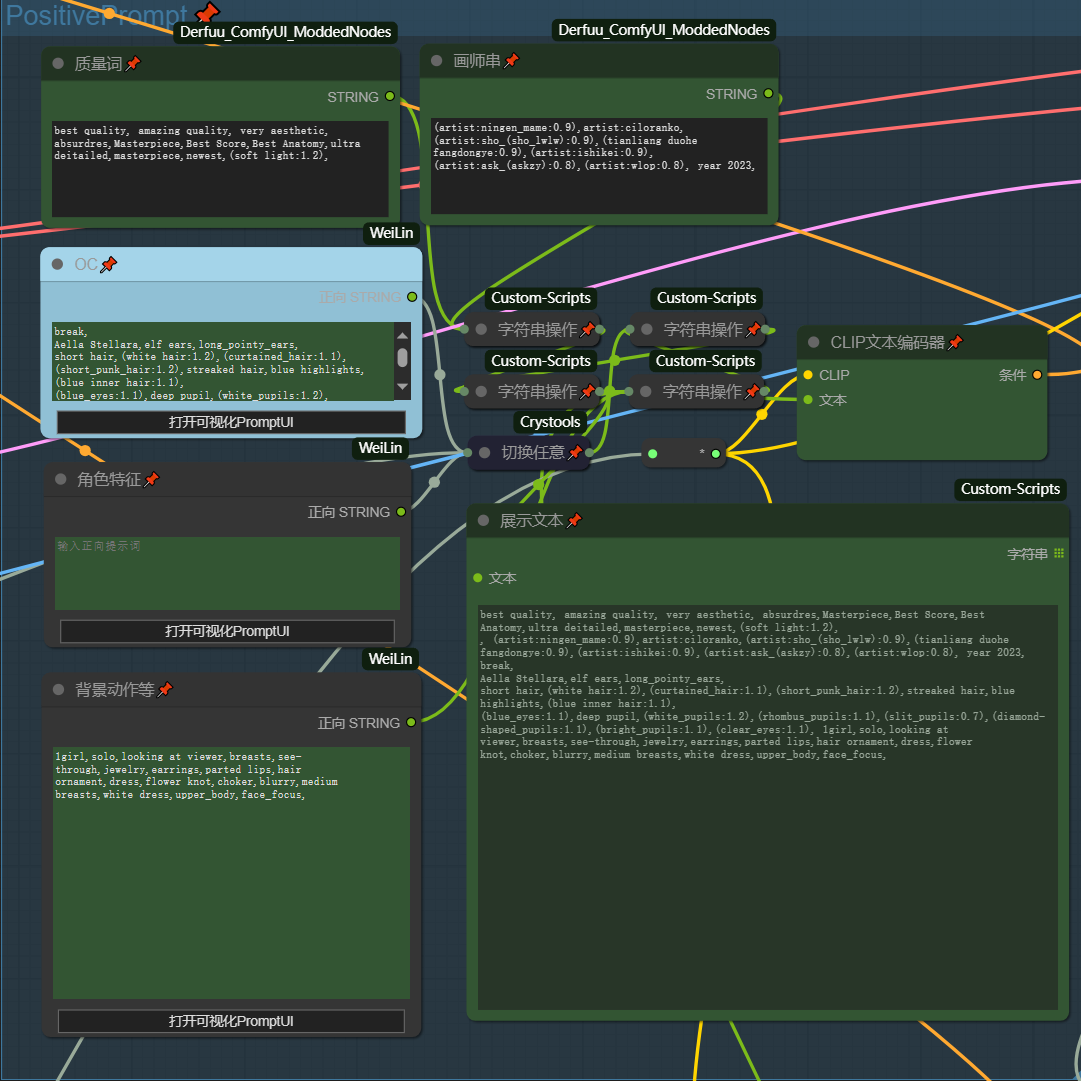
对于此模块唯一需要说明的一点是:在关闭OC_Mode后OC字符框将被屏蔽,转而使用角色特征字符框,反之亦然 换言之 OC 和 角色特征 二者互斥
Sample&SeedControl
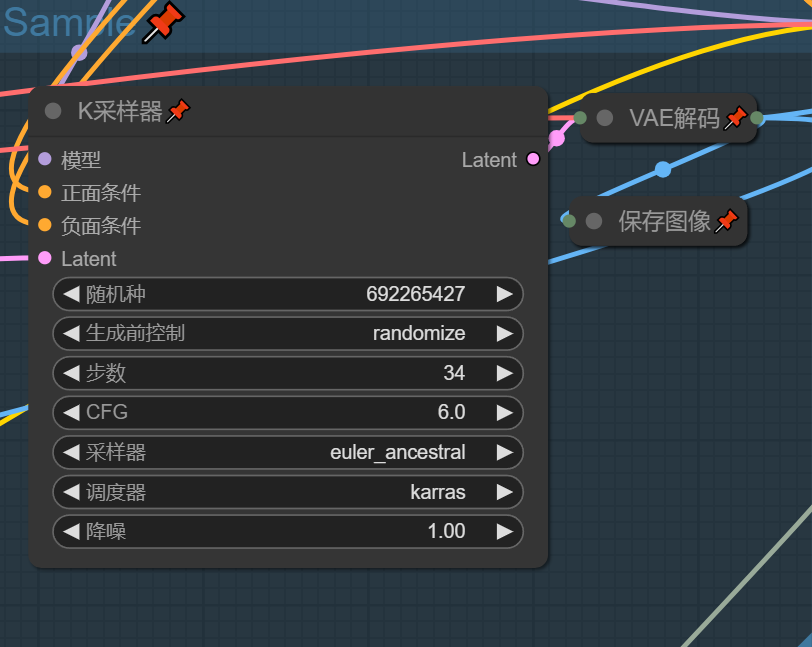
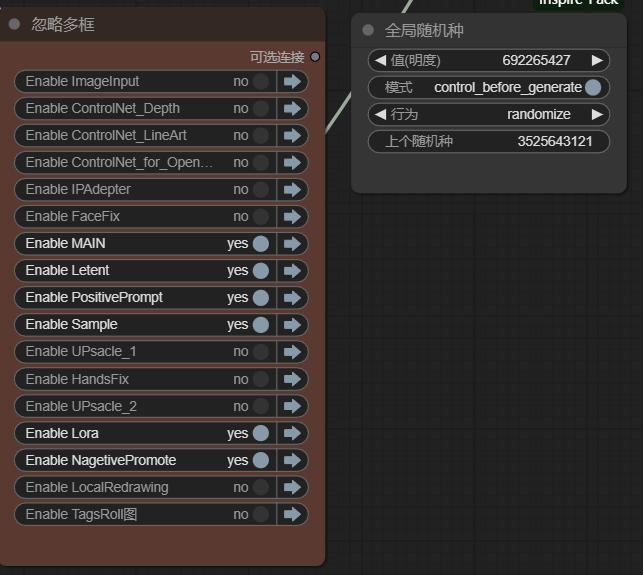
全局种子可使图片被二次生成,其他没什么好说的
IPAdepter
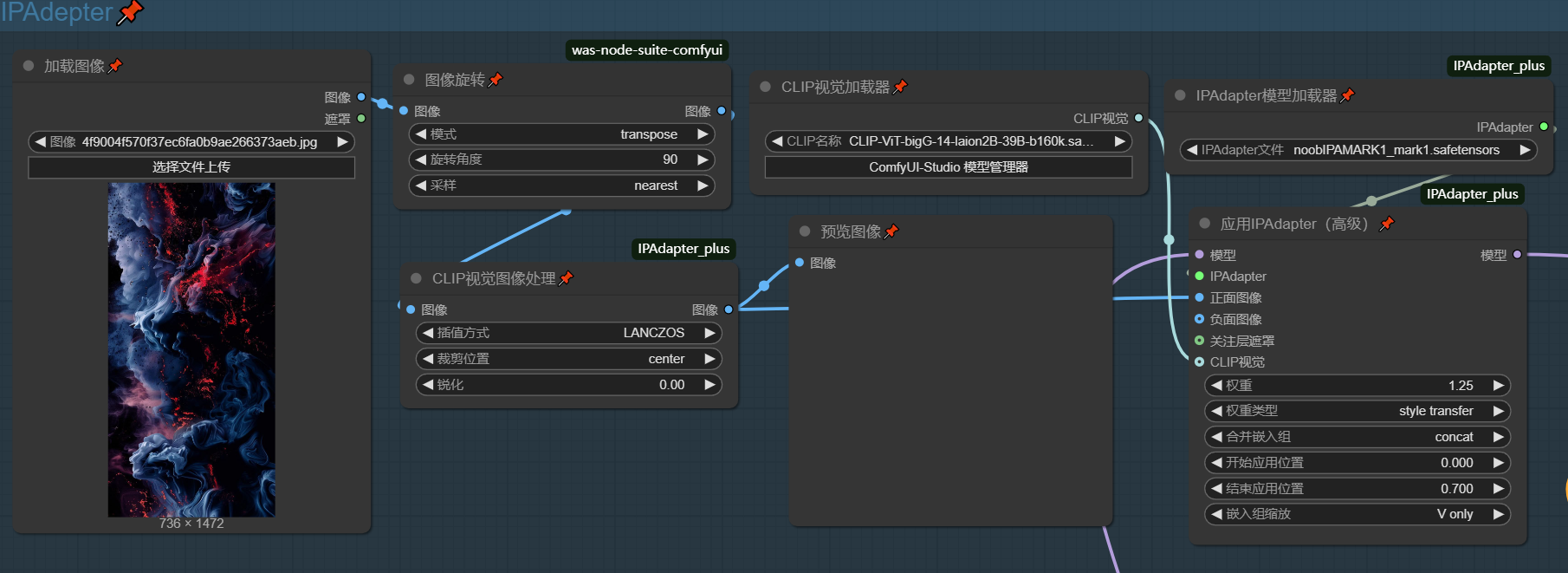
简单来说就是画风迁移,使用模型为 NOOB-IPA ,画风偏移的源图片可以去
Pinterest 上寻找Controlnet
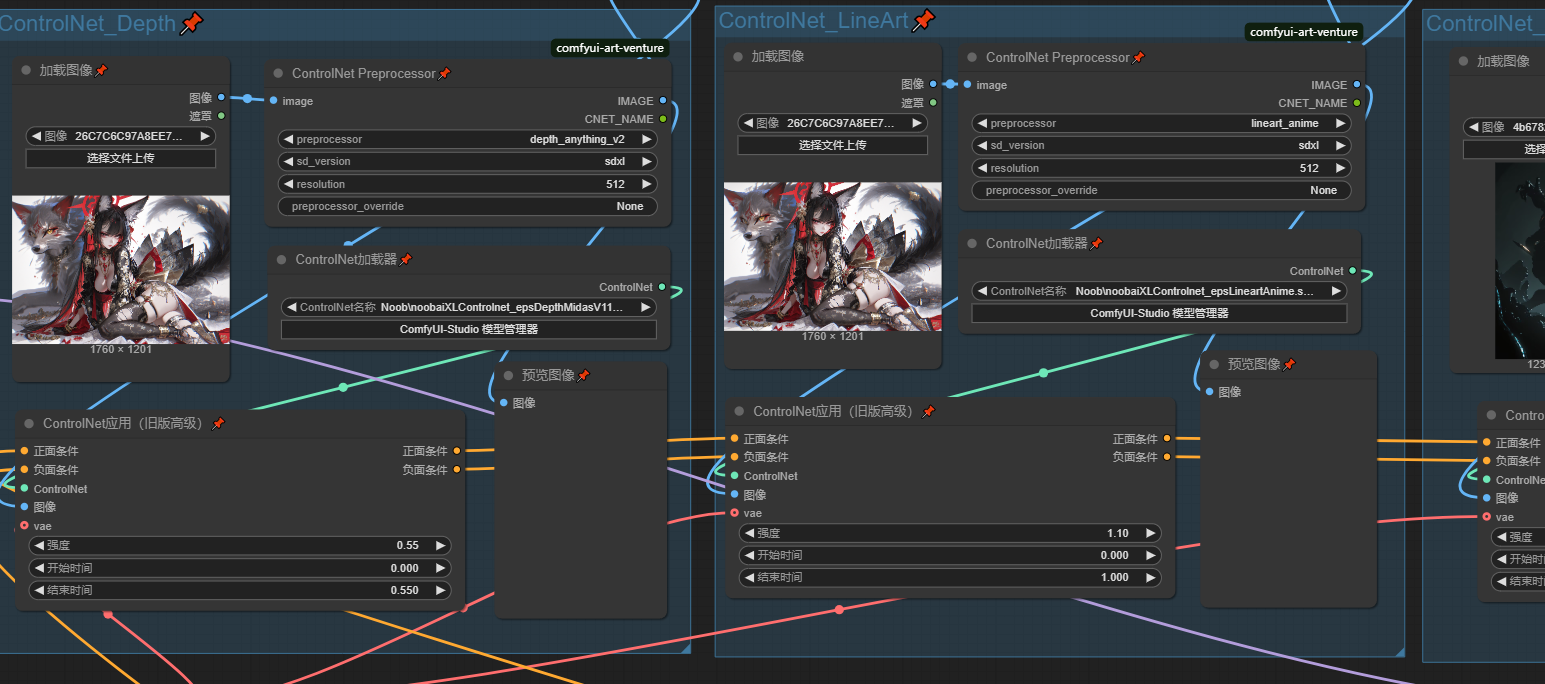
在日常使用中Controlnet最常用的模型有 LineArt , Canny , Depth , OpenPose 配合提示词反推使用可以很好的复刻和差分图片,
值得注意的是:lineart在提起线稿是会丢失一些细节线条,而canny会尽可能详尽的提取线稿,我们在实际使用时需要结合二者特性对线稿进行处理,具体用法我会在接下来的Controlnet_Preprocessor工作流中讲解
TagsRoll图
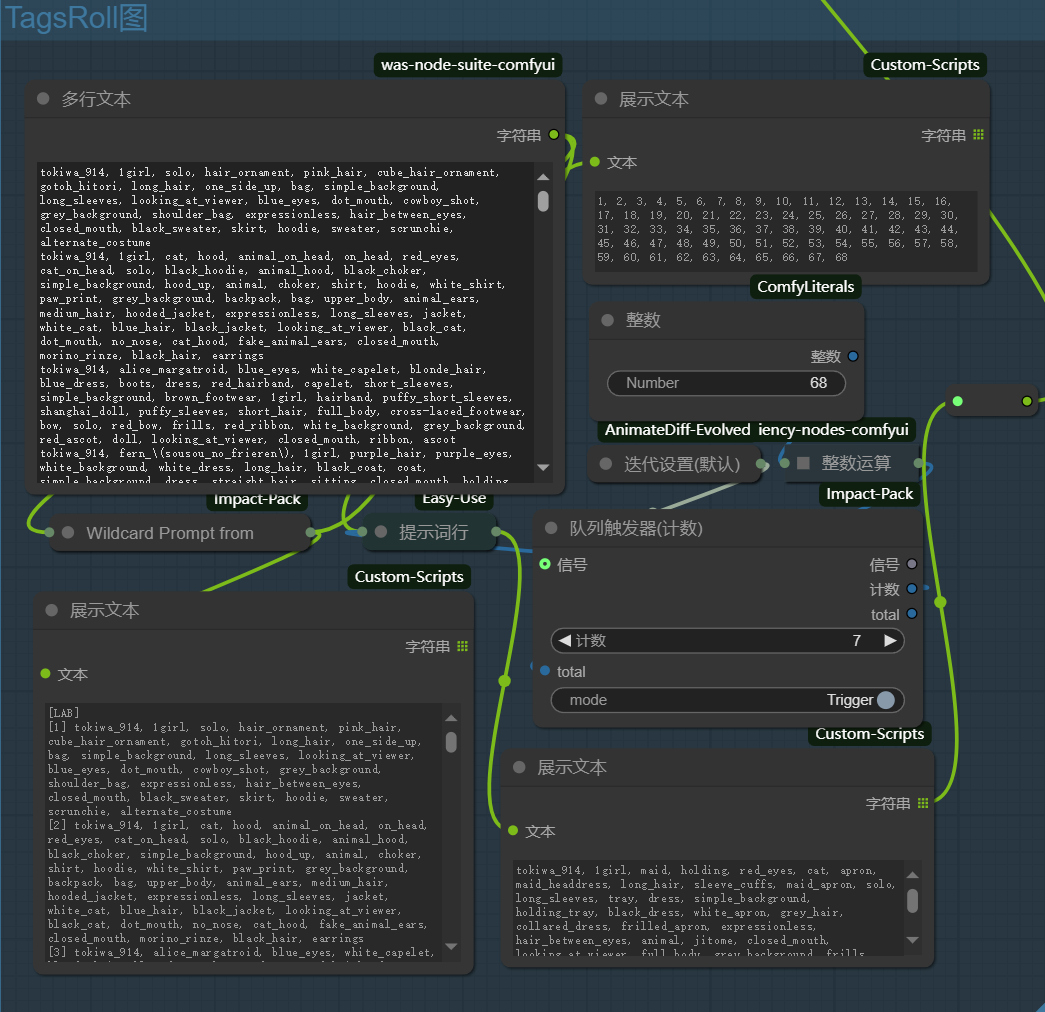
以迭代器为核心的自动roll图模块,以换行为分隔符进行提示词分组然后迭代输出提示词
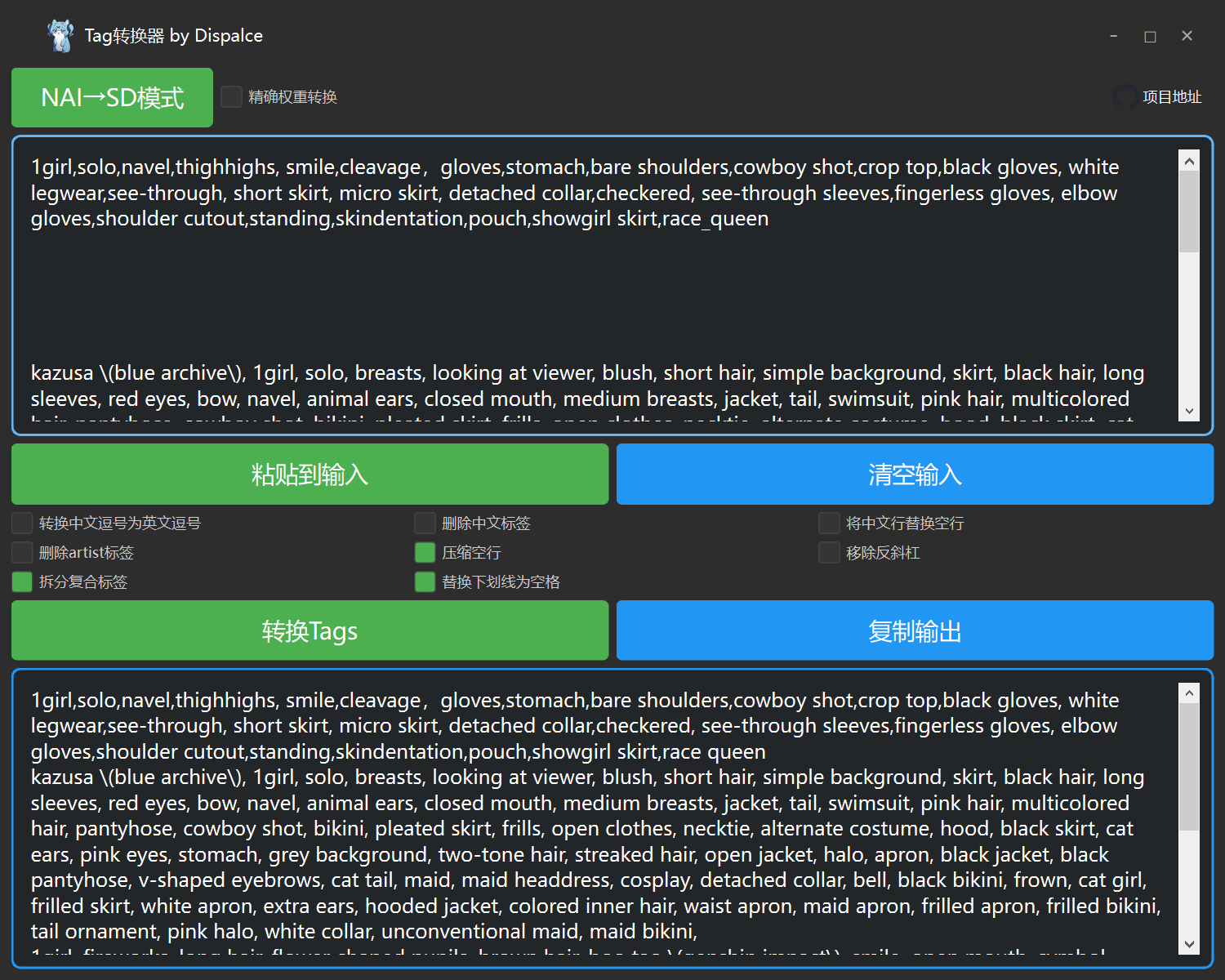
首先在使用前你需要将收集的提示词做好整理,每组提示词一行,输入到文本框内,为此开发了一个提示词处理器 TagConverter
![]()
它可将NAI提示词与SD提示词进行转换,并压缩空行时提示词转换为TagsRoll图可用的格式,
在输入提示词组后关闭Sample模块和其他需要采样的模块,将迭代器次数改为1,执行队列,进行初始化
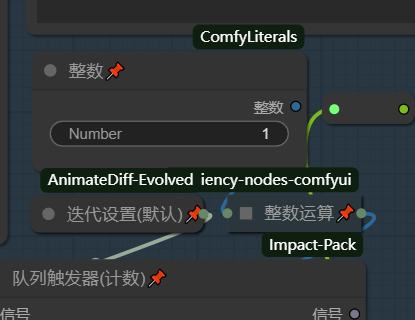

初始化后你会看到你的提示词组数
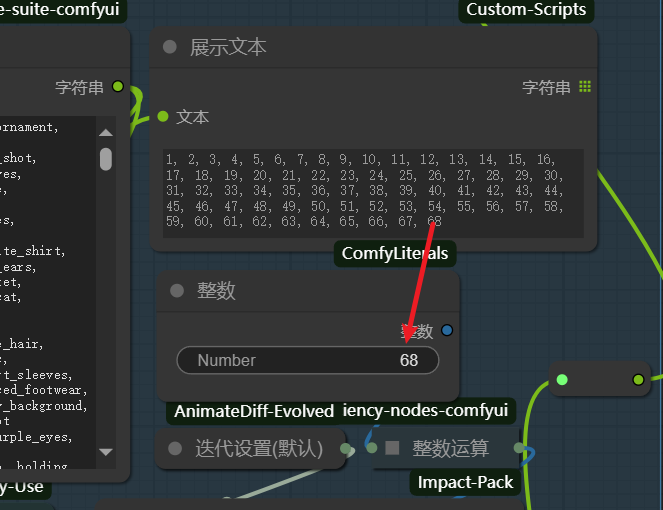
将最后的组索引填入迭代器中,启用Sample模块,再次执行队列时tagroll图会按顺序将提示词组输入到PositivePromot中,你可以在队列触发器的计数栏看到当前roll到了第几组提示词,并在下方看到提示词
SP:注意迭代器运行时是全局迭代,如果你在此时切换工作流会导致bug,所以roll图的时候可以先去干别的事情,再者,正式roll图前确保你的PositivePromot中没有你不想要的通用提示词,否则roll半天就白费力气了
LocalRedrawing
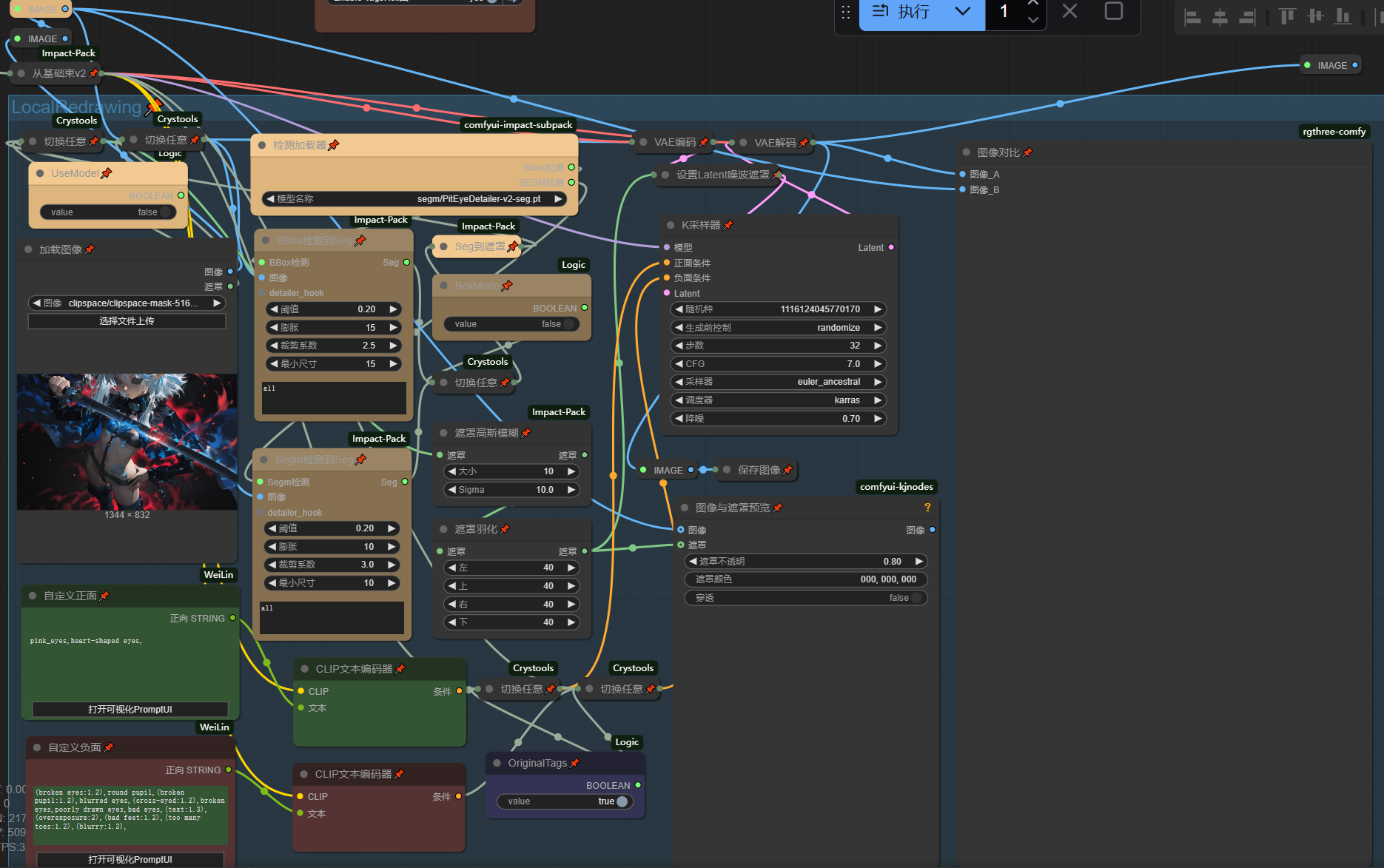
此模块支持模型检测生成遮罩重绘和手动绘画遮罩进行重绘,还可以选择使用原始提示词来roll图得出更好的结果,或者使用新的提示词来改变局部特征
通常使用时我会在多个原始图像中挑选几个瑕疵较小的进行局部重绘,直接将生成的图像拖进ComfyUI中,然后关闭Sample模块,再将图片拖入加载图像,进行局部重绘,
启用UseModel时蒙版由检测模型生成,你需要根据不同的模型类型来切换BoxModel
关闭UseModel时右键图像加载器进入手动蒙版编辑界面画出你期望的蒙版,蒙版结果会直接在图像加载器上显示出来
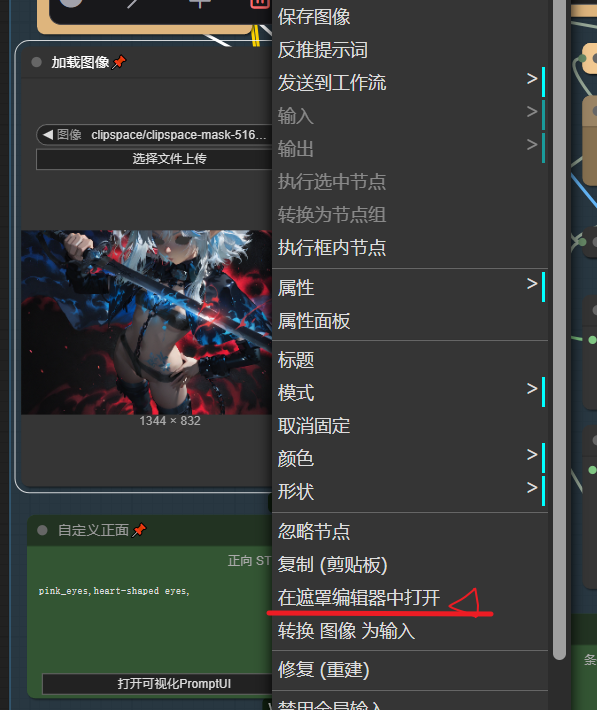
SP:图片导入ComfyUI时全局种子是固定的,应改为随机
FaceFix & HandsFix
二者本质也是模型检测获得蒙版进行局部重绘,没有什么特别的东西
UpScale
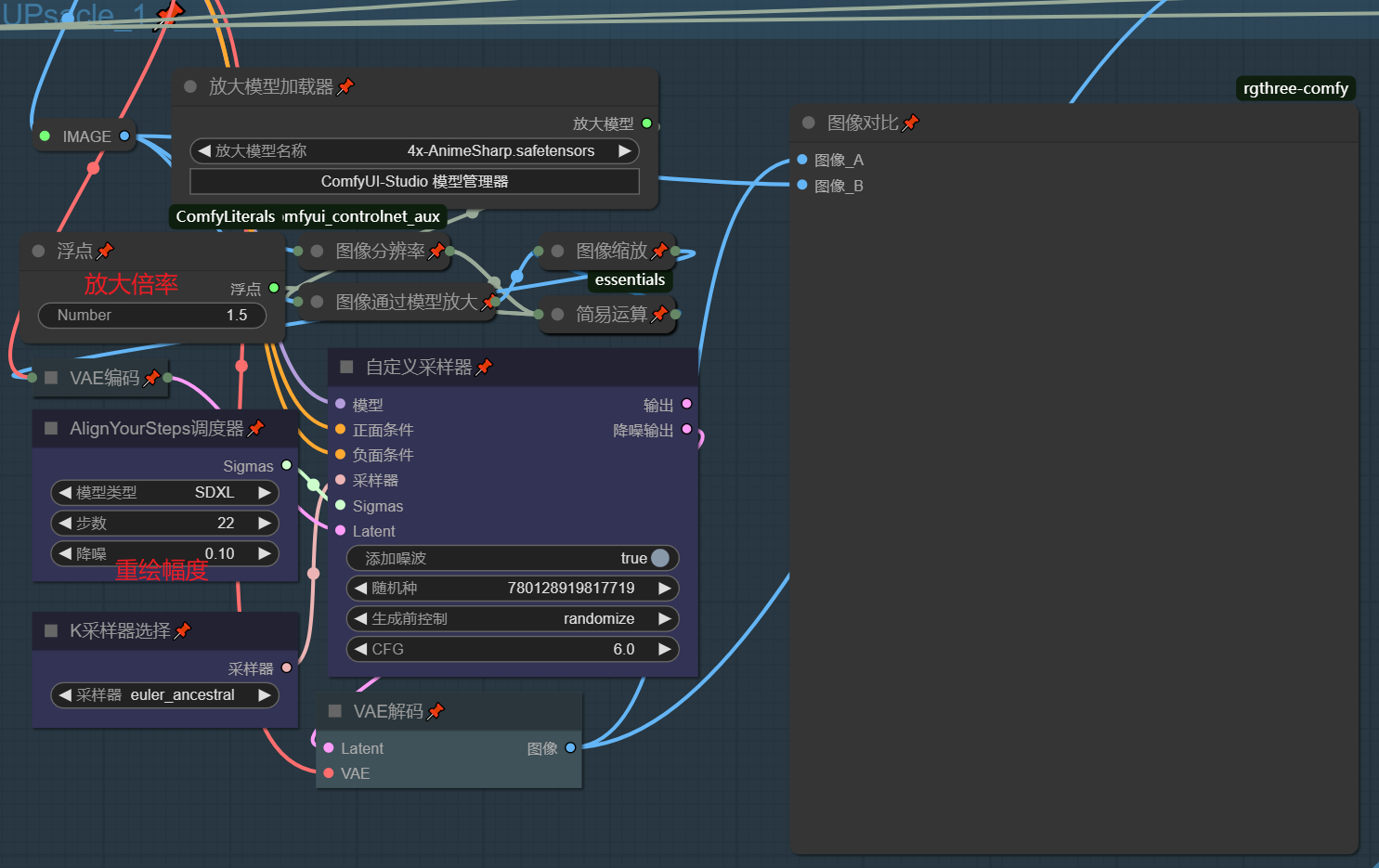
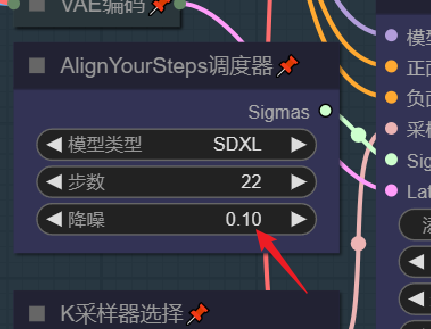
首先使用模型放大,再使用算法缩小,得到期望的放大倍率,最后对缩放后的图像进行低噪声的重归,来对冲放大导致细节扭曲,你可以通过调整噪声大小来决定图像输出与原图像的差别
通常在使用时我会先将原图像放大1.5倍使得手,脸,眼睛获得更多的像素,方便后续重绘增加细节(过大的图像重绘对性能要求较高,1.5倍放大是我的经验之谈,你应根据实际情况来选择放大倍率)
工作流最后也有一个UpScale模块,这次的放大我会给到一个较高的倍率,来放大已经重回好的图像
自定义后期处理顺序
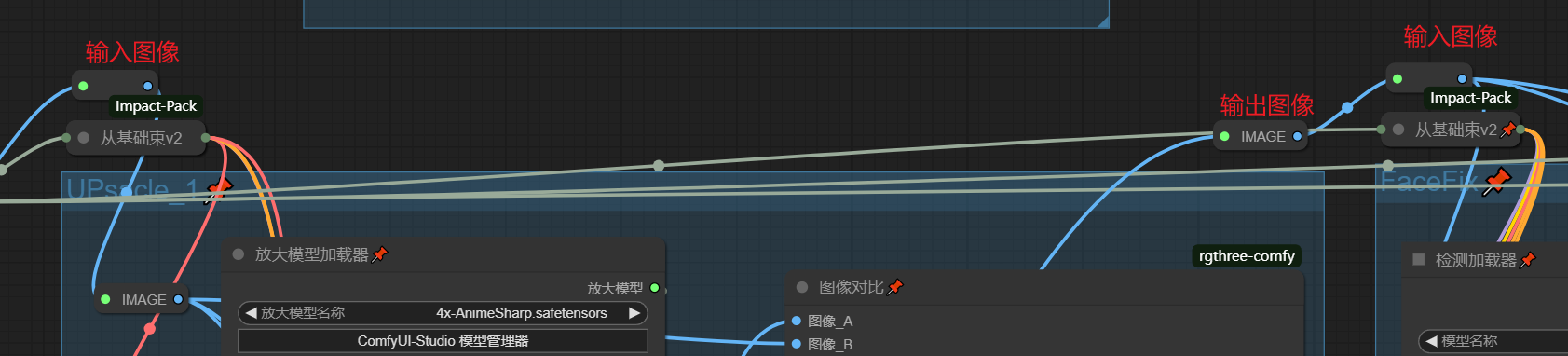
如果你仔细观察我的工作流可以发现UpScale,FaceFix等后期模块上方都留有图像输入和输出转节点,你可以按照自己的需要求来调用模块
Controlnet_Preprocessor
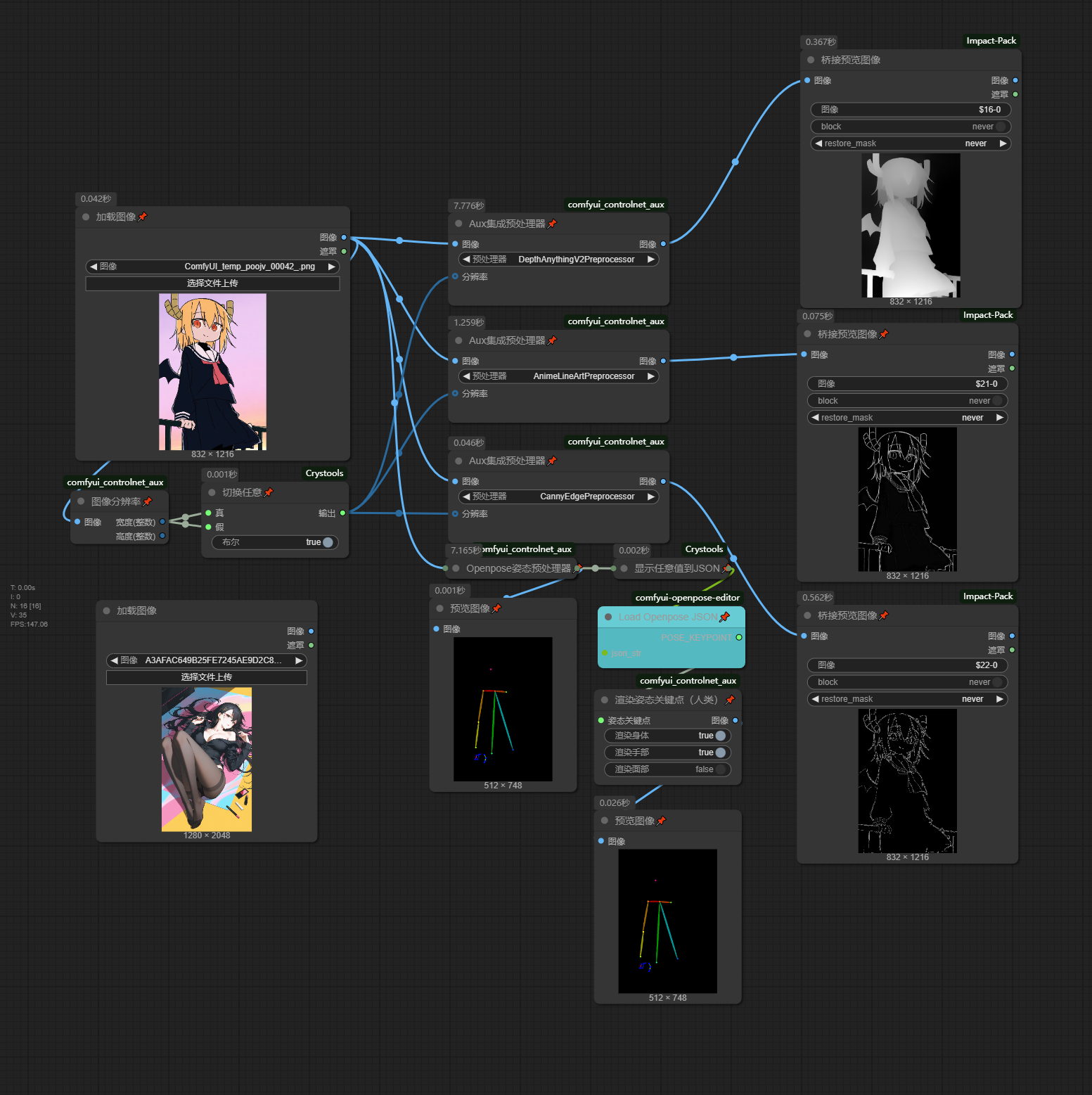
LinePreprocessor
在使用ControlNet时提前处理好输入数据能得到更好的输出效果,此工作流便是用于处理Lineart,Canny,Depth,OpenPose的输入数据的
正如上文我在Controlnet章节提到Lineart和Canny的优缺点,我们需要扬长避短的来处理线稿
在处理线稿时我会有时将Lineart和Canny一起导入编辑器,将二者叠加然后扬长避短的进行修改
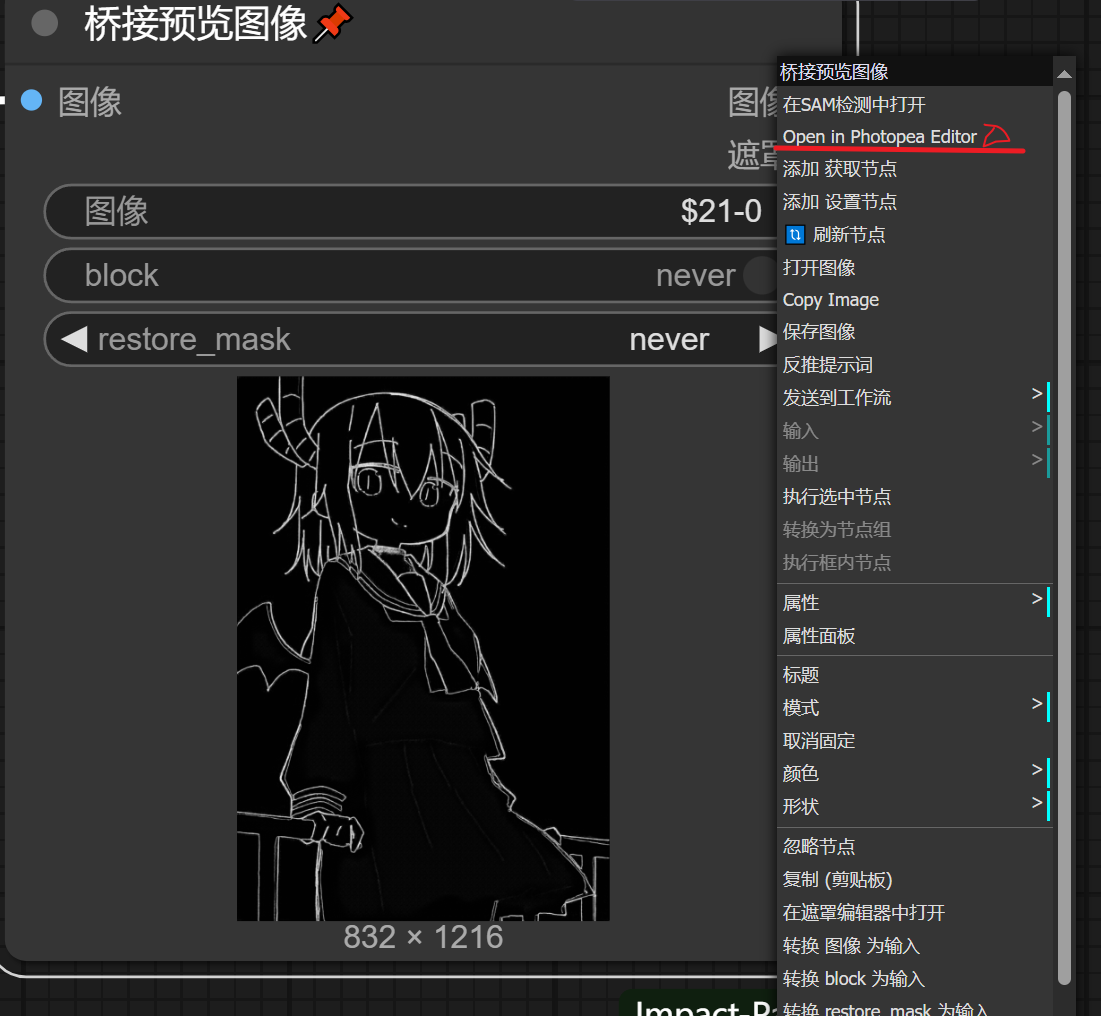
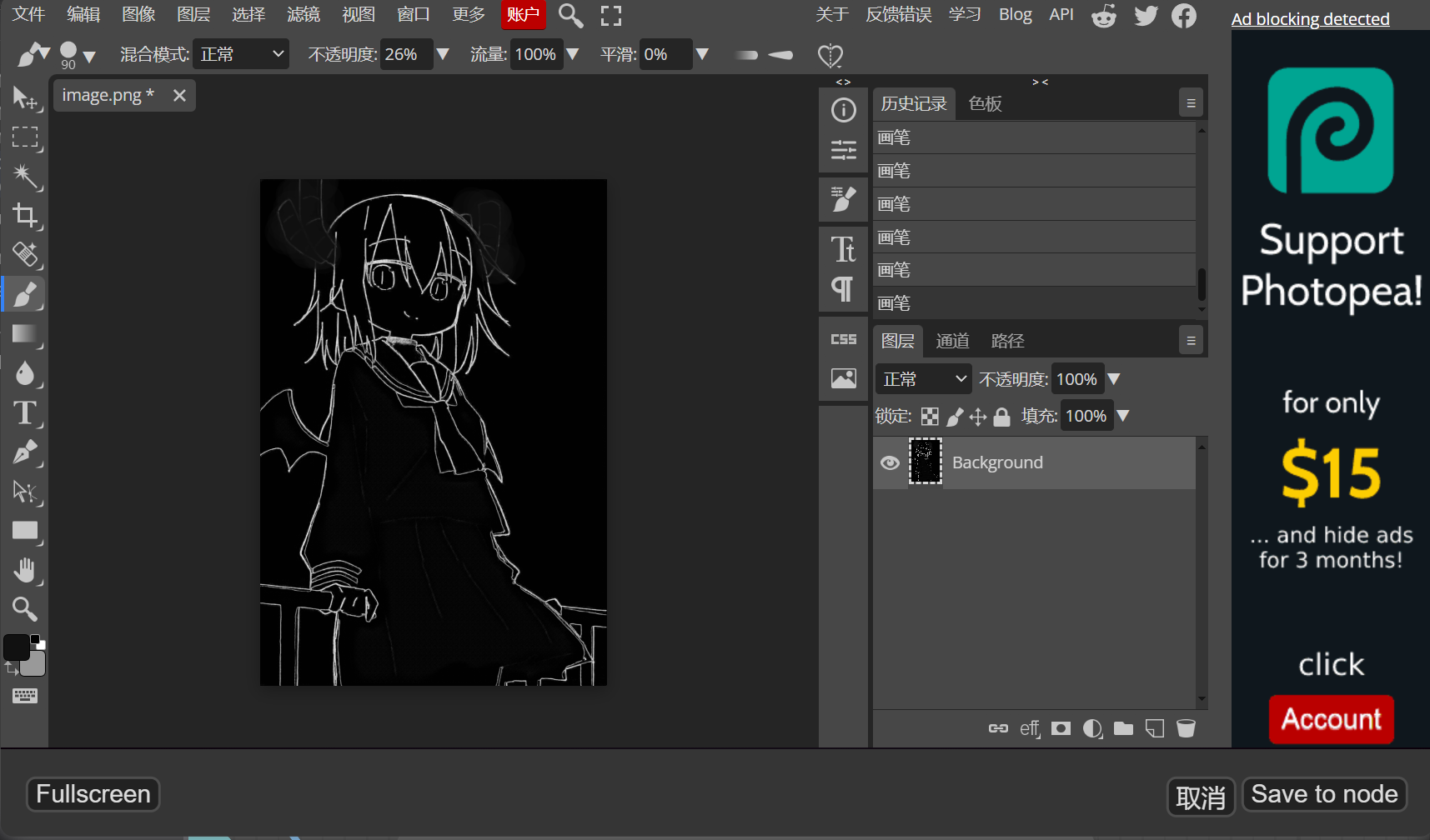
OpenposePreprocessor
说实话,我一直觉得的poenpose的效果不是很尽如人意(可能是我比较菜),因此一般我使用的较少
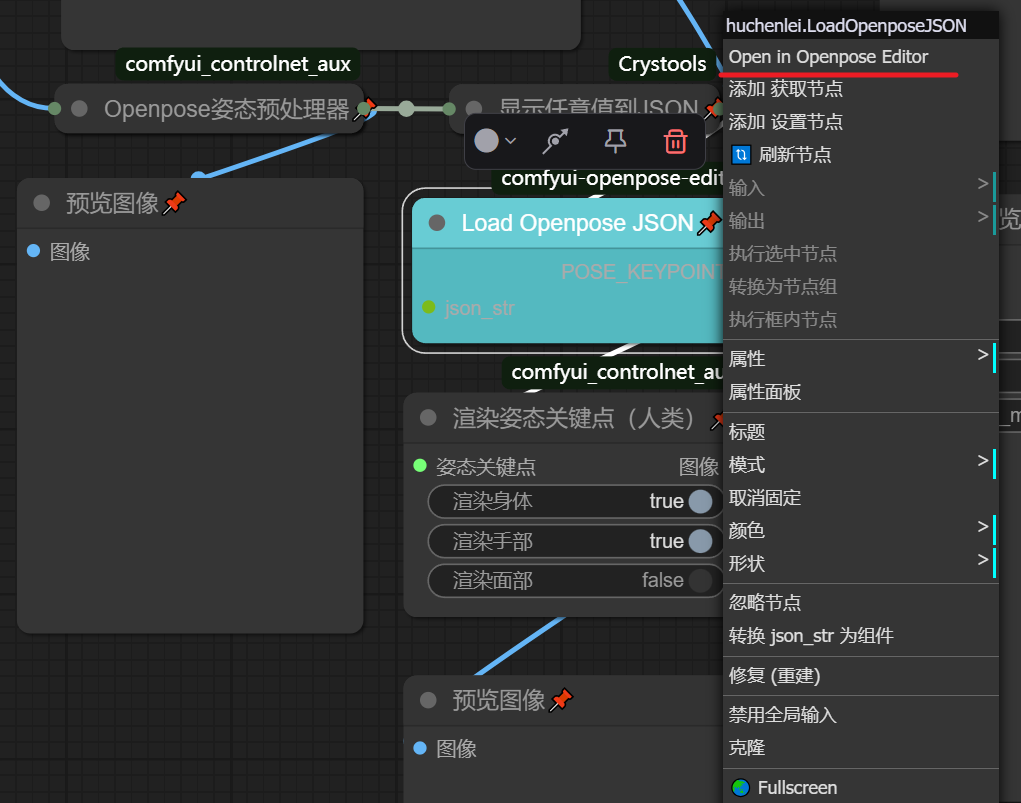
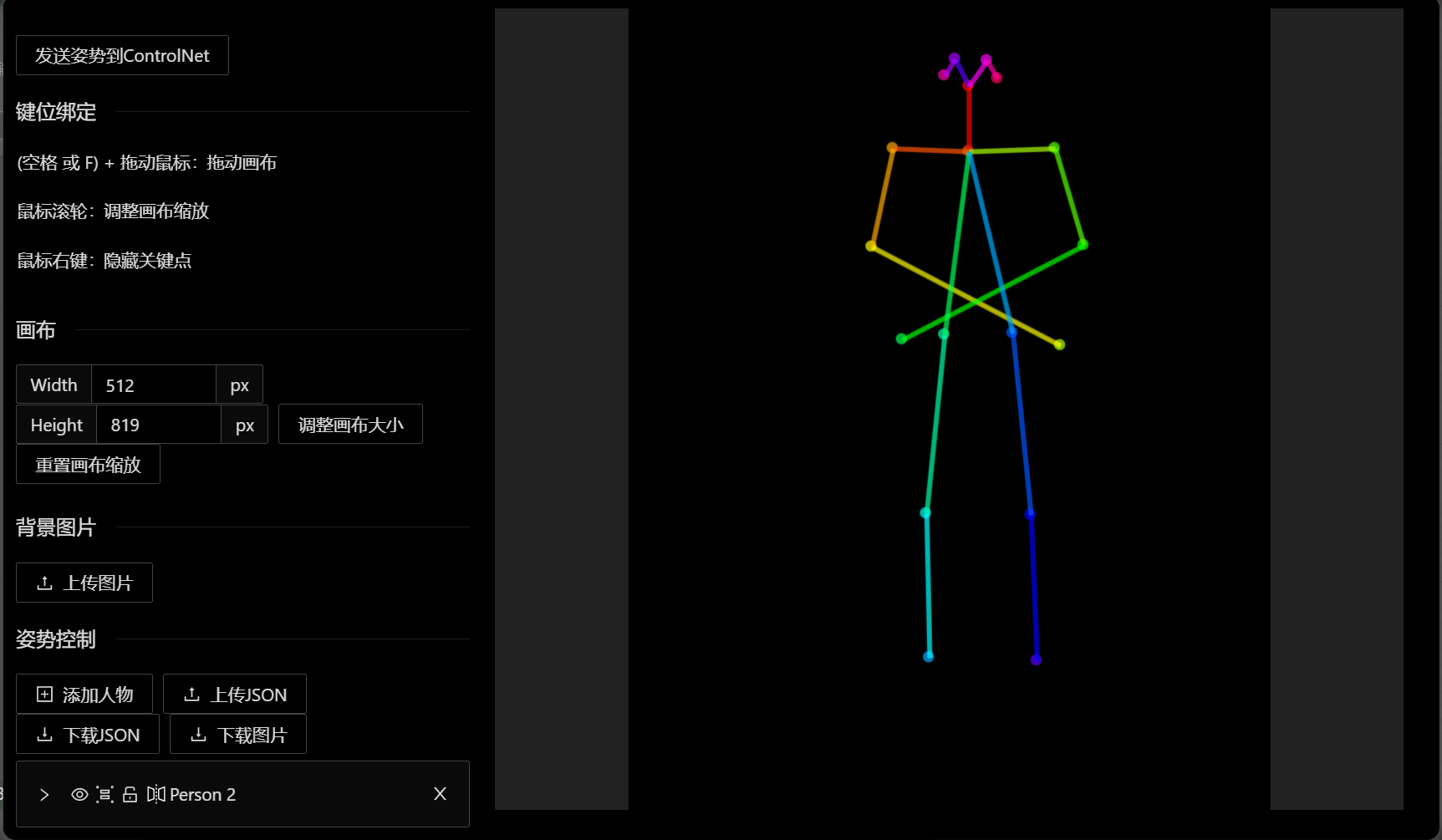
右键点击Load Openpose JSON进如Openpose编辑界面简单的拖动一下火柴人的关节就算是编辑好了pose了,最后下载图片可以给controlnet的openpose模型使用的了
Wd14_reasoning backward
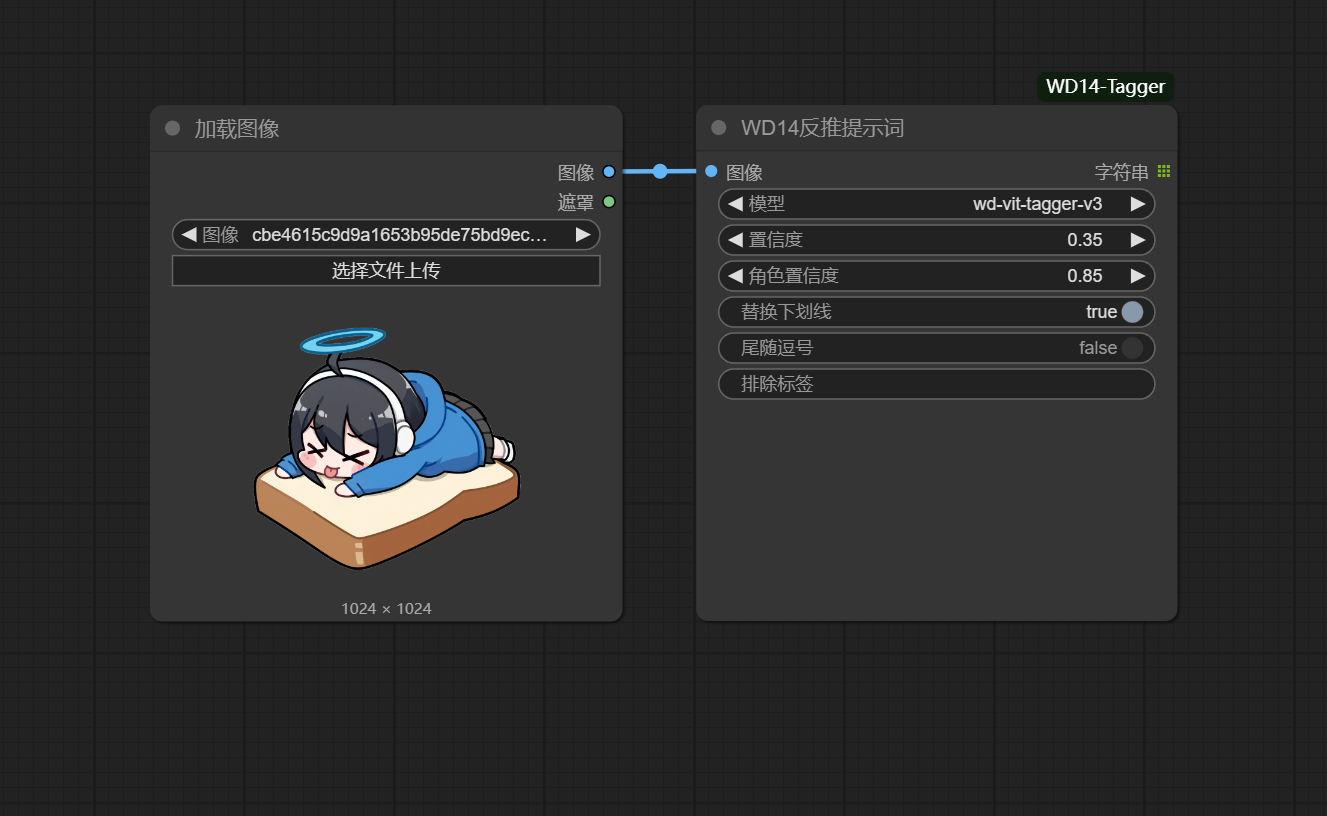
推荐使用wd-vit-tagger-v3模型反推,好用,爱用
结语
这篇文章总结了我进行ai艺术创作的全部流程,每个章节的头图拖入ComfyUI就可以直接使用我的工作流,文中错误和不足的地方欢迎指正
最后感谢开源社区每个模型和插件的开发者,正是有了他们的无私贡献,才能有这篇文章
- Title: ComfyUI_AnimeWorlkflow
- Author: Displace
- Created at : 2025-04-16 00:00:00
- Updated at : 2025-04-18 13:27:30
- Link: https://mikumikudaifans.github.io/Displace.github.io/2025/04/16/NoobXL_AnimeWorkFlow/
- License: This work is licensed under CC BY-NC-SA 4.0.